External app / Live / LLM evaluation / data systems engineering
SpiderLens
A controlled evaluation framework and explainer comparing Text-to-SQL with Direct Table QA over relational data.
Why it exists
SpiderLens started from a practical evaluation question: when an LLM answers questions over relational tables, is it better to ask for executable SQL or to serialize table rows and ask for the answer directly?
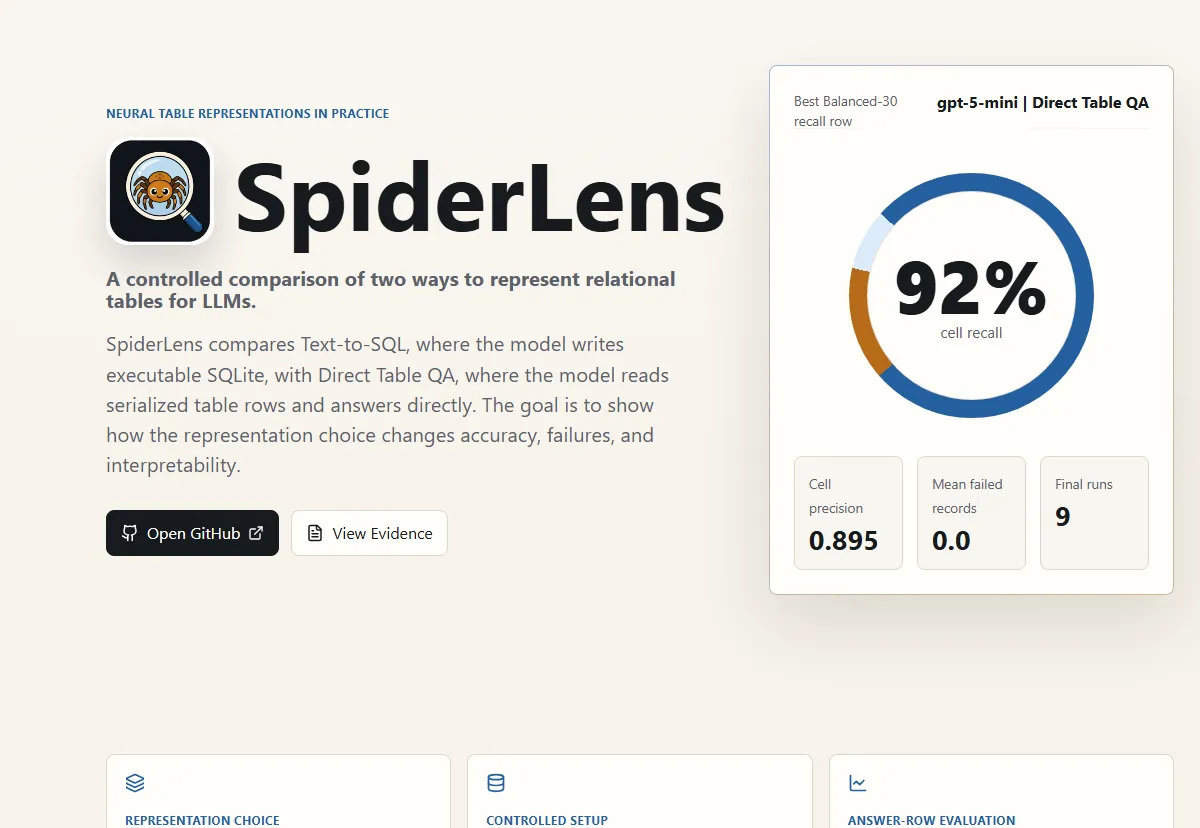
The project keeps that comparison controlled. The main Balanced-30 experiment uses 30 Spider development examples, 10 databases, oracle relevant tables, three fresh repeats per model, and the same answer-row scoring target for both pipelines.
The result is both a Python framework for running the experiment and an interactive explainer for reading it. The public site shows the pipelines, headline metrics, failure examples, evidence tables, and reproducibility settings behind the claims.
Build choices
The Python side owns the data work: manifest loading, SQLite access, prompt versions, table serialization, SQL execution, answer parsing, normalization, evaluation, and report generation. Text-to-SQL writes a SQLite query that gets executed locally; Direct Table QA reads compact serialized table content and returns answer rows directly.
The experiment treats retrieval as intentionally out of scope. Both pipelines receive the same preselected relevant tables, so the comparison focuses on representation, answer generation, execution failures, and output-data quality rather than table discovery.
The Astro companion site is a static reading layer over stored artifacts. It packages the Balanced-30 results, diagnostic examples, run IDs, evidence index, and Mark 2 stress-test sequel into a form that is easier to inspect than raw reports alone.
What it proves
- Representation choices change both accuracy and failure modes.
- SQL stays useful because executable queries are cheap, inspectable, and easy to debug when schema linking succeeds.
- Direct Table QA can reduce SQL execution failures and recover answer rows well, but pays more context and serialization cost.
- Evaluation is clearer when both approaches are judged by the data they return, not by whether the intermediate answer looks plausible.
- A research-style experiment can ship with a reproducible artifact trail and a public interface that makes the tradeoffs readable.